


ALL-IN-ONE PLATFORM
esDynamic
Manage your attack workflows in a powerful and collaborative platform.
Expertise Modules
Executable catalog of attacks and techniques.
Infrastructure
Integrate your lab equipment and remotely manage your bench.
Lab equipments
Upgrade your lab with the latest hardware technologies.


PHYSICAL ATTACKS
Side Channel Attacks
Evaluate cryptography algorithms from data acquitition to result visualisation.
Fault Injection Attacks
Laser, Electromagnetic or Glitch to exploit a physical disruption.
Security Failure Analysis
Explore photoemission and thermal laser stimulation techniques.



EXPERTISE SERVICES
Evaluation Lab
Our team is ready to provide expert analysis of your hardware.
Starter Kits
Build know-how via built-in use cases developed on modern chips.
Cybersecurity Training
Grow expertise with hands-on training modules guided by a coach.




ALL-IN-ONE PLATFORM
esReverse
Static, dynamic and stress testing in a powerful and collaborative platform.
Extension: Intel x86, x64
Dynamic analyses for x86/x64 binaries with dedicated emulation frameworks.
Extension: ARM 32, 64
Dynamic analyses for ARM binaries with dedicated emulation frameworks.
DIFFERENT USAGES
Penetration Testing
Identify and exploit system vulnerabilities in a single platform.
Vulnerability Research
Uncover and address security gaps faster and more efficiently.
Malevolent Code Analysis
Effectively detect and neutralise harmful software.
Digital Forensics
Collaboratively analyse data to ensure thorough investigation.




EXPERTISE SERVICES
Software Assessment
Our team is ready to provide expert analysis of your binary code.
Cybersecurity training
Grow expertise with hands-on training modules guided by a coach.

INDUSTRIES
Semiconductor
Security Labs
Governmental agencies
Academics

ABOUT US
Why eShard?
Our team
Careers



FOLLOW US
Linkedin
Twitter
Youtube
Gitlab
Github





Analyzing CVE-2020-15999 with esReven: Buffer-overflow in libpng in Chrome


In this article, we will present a step-by-step analysis of an exploit for CVE-2020-15999 using esReverse. CVE-2020-15999 is a heap buffer overflow in Freetype allowing a remote attacker to potentially exploit heap corruption via a crafted HTML page. In the process, we will show how esReven’s timeless features such as Symbol call Search, Memory History and backward Taint can be combined to build a root-cause analysis.
Recording of the scenario
The record was done manually, using this exploit. From esReven’s Project Manager, it was started after entering the URL of the exploit file and stopped when Chrome reported that the tab crashed.
The resulting trace for this scenario contains ~ 3 billion instructions, with certainly some overhead (exception management from the OS and Chrome) due to the fact that we chose a manual recording approach. We could have optimized our recording approach using some ASM stubs to stop the record earlier in the Chrome executable. In this case, we felt this was not necessary since the analysis went smoothly.
Detection of the crash
As Chrome is “catching” the crashes of each of its tabs to display that the tab crashed to the user we should look at the symbol KiUserExceptionDispatch in ntdll.dll.
From there (as there is only one), we can see what is causing the exception by moving to the corresponding exception (using the esReven % shortcut on the previous iretq) and it’s a pagefault.

The dereferenced address is coming from the memory ds:0x20dd33e10a0 (qword ptr [rcx]) with the value 0x7fff00000000. Is this address ok?
Detection of the buffer overflow
If we look at it in the Memory History view, we can see that the address was written previously in chrome.dll and that 4 bytes of it were reset to 0 inside cr_png_combine_row in libpng (statically linked in chrome.dll). The reset of only 4 bytes of an address in a function called cr_png_combine_row looks suspicious, do we know if there is an issue in cr_png_combine_row itself or if it was called with bad parameters?
The prototype of cr_png_combine_row is cr_png_combine_row(png_structp png_ptr, png_bytep row, int display) and for this particular call we have cr_png_combine_row(0x20dd3489a40, 0x20dd33e10a0, 0x0). As we can see, the second parameter that should contain the destination buffer of the function is the same address that was overwritten and which contained the address used later. It looks like the faulty function is not cr_png_combine_row but someone giving it this address as 2nd parameter.
Where is this address passed to cr_png_combine_row coming from?
If we taint the address backward to see where the argument 0x20dd33e10a0 of cr_png_combine_row is coming from, we reach this transition inside a loop:
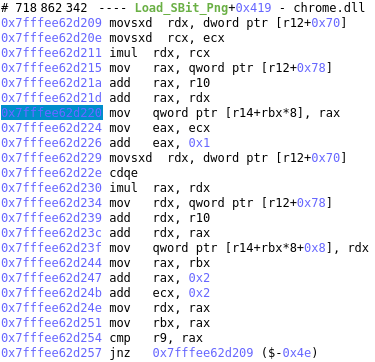
The value written is 0x20dd33e10a0 and it’s computed from [r12 + 0x78] + r10 + rcx * [r12 + 0x70] with:
- [r12 + 0x78] = 0x20dd33e04e0
- r10 = 0x0
- [r12 + 0x70] = 0x4
- rcx = 0x2f0
Something must be wrong in here as 0x20dd33e10a0 is pointing to a value that isn’t related to the png.
If we look at the loop:
-
r12 seems to point to a structure with one field at the offset 0x70 and one at 0x78.
- Neither of these fields change during the loop.
- The field at 0x78 looks like a pointer.
-
r10 doesn’t change during the loop.
-
rcx looks like a counter in the loop
The “array” in which the values are stored (pointed by r14) during the loop is given as the second argument of png_read_image whose prototype is png_read_image(png_structp png_ptr, png_bytepp image) with png_bytepp being a png_byte (so an array of pointer to array of png_byte, aka an array of pointer to rows of pixel components).
The loops make perfect sense if the field at 0x70 is the pitch of the image (width * number of components per pixel) as computing the address of one row will give us: buffer + i * image_pitch with i from 0 to the image height. With that, we still don’t know where r10 is coming from but it’s probably an offset in the buffer or something like that.
In pseudo code, the loop looks like that:
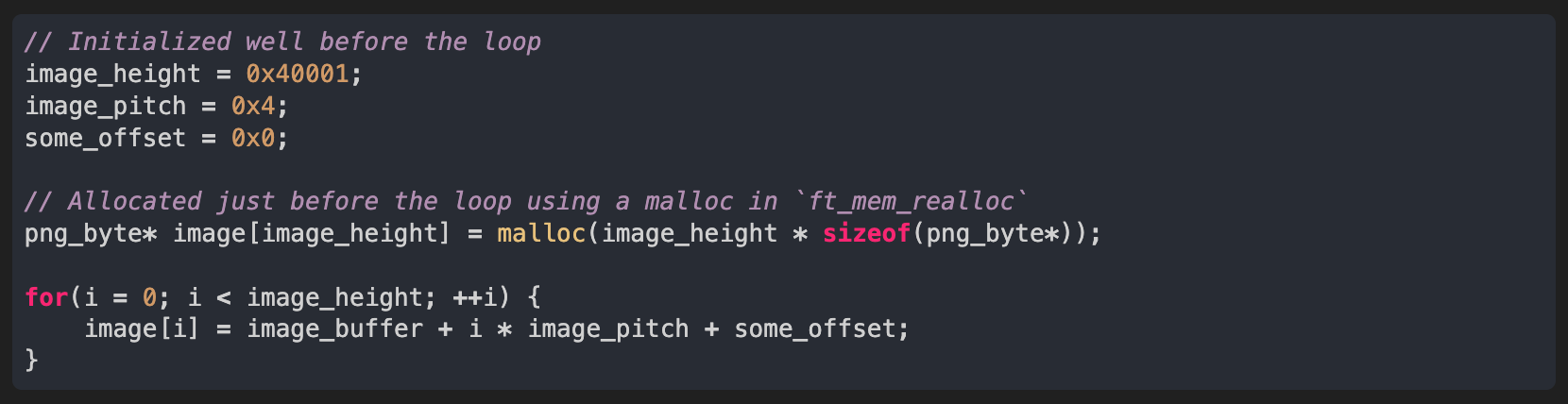
As the loop looks logical and I don’t see anything wrong with the breaking condition we have two possibilities to explain what is going wrong:
- image_height and/or image_pitch are too big
- The image_buffer is too small
Are image_height and/or image_pitch too big?
If we taint the pitch (tainting [r12 + 0x70]), we directly reach an IHDR header with the width being partially tainted.
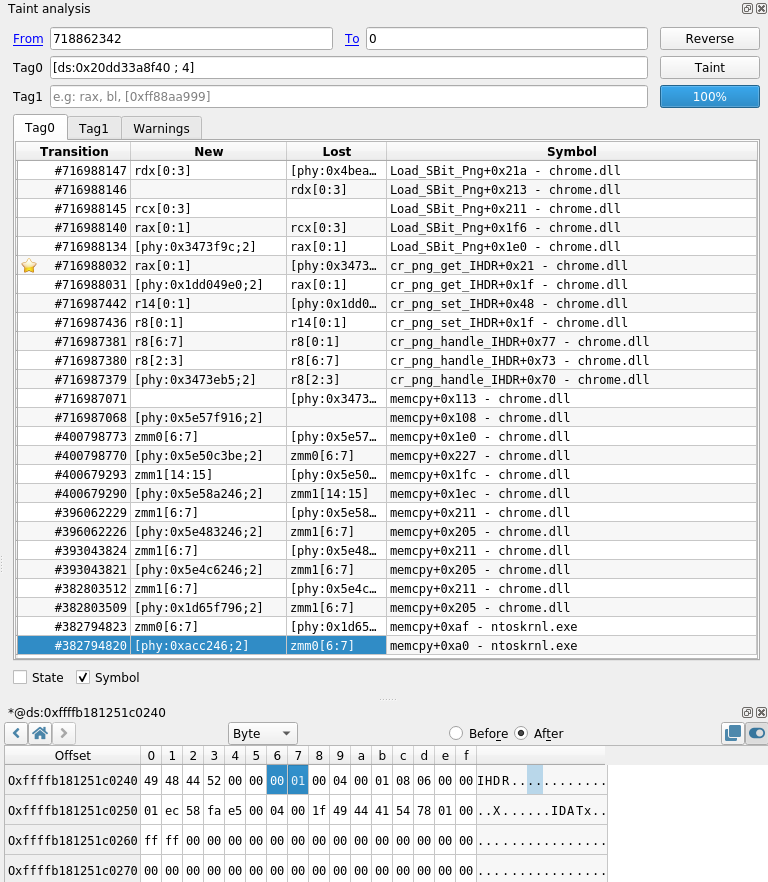
The IHDR header is being copied from a buffer inside a NtReadFile (looks like the header is coming from our font file).
If we look at the values in this header we have:
- width: 0x1
- height: 0x40001 (looks like we also prove that image_height is correct)
- bit depth: 0x8
- color type: 0x6
With these values, from the png documentation, each pixel should have four components (RGBA) with a size of 8 bits each, meaning that the pitch should be 4 bytes which proves that image_pitch is correct.
Looks like neither image_height nor image_pitch are too big in the loop.
Is the image buffer too small?
If we taint the address of the buffer (tainting [r12 + 0x78]) we can see that it is coming from the return value of a malloc.
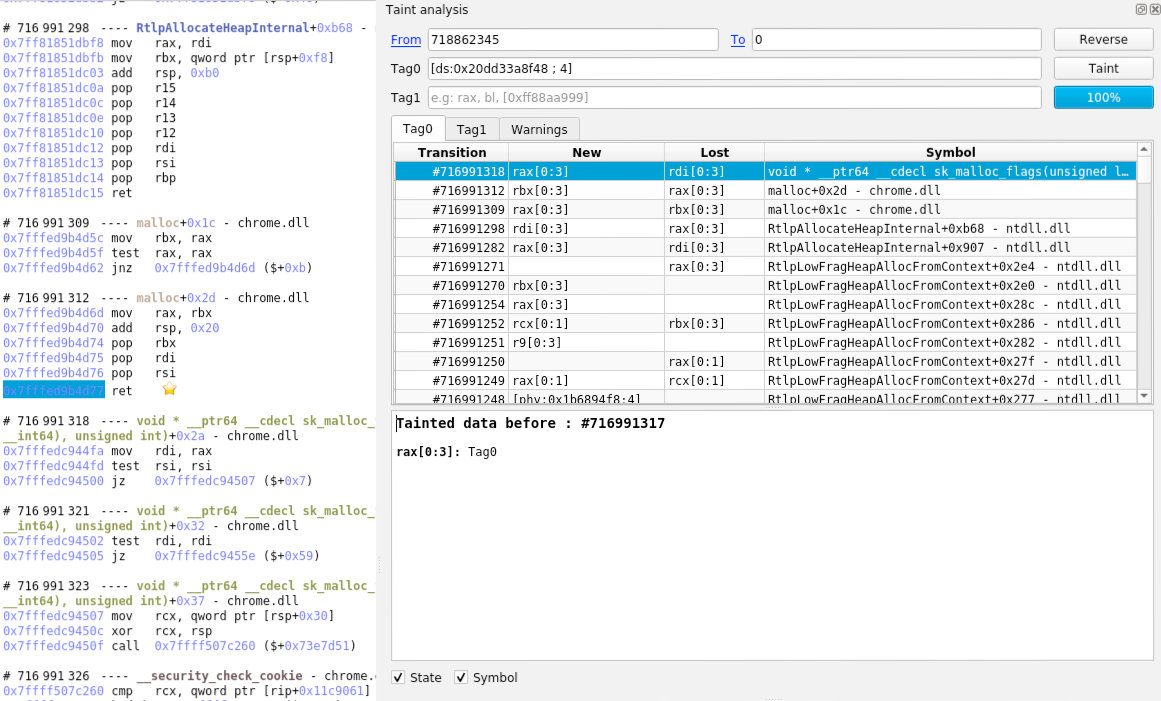
If we go to the call to malloc to check the size given in parameter, we would expect the value height * width * bpp = 0x40001 * 0x1 * 4 = 0x100004 but the actual size given is… 0x4 ?! The size given to malloc looks clearly wrong.
Where does the size of the image buffer come from?
If we taint backward the size (rcx at the call of malloc), we can see that, at the end, the width and the height are partially tainted in the IHDR header.
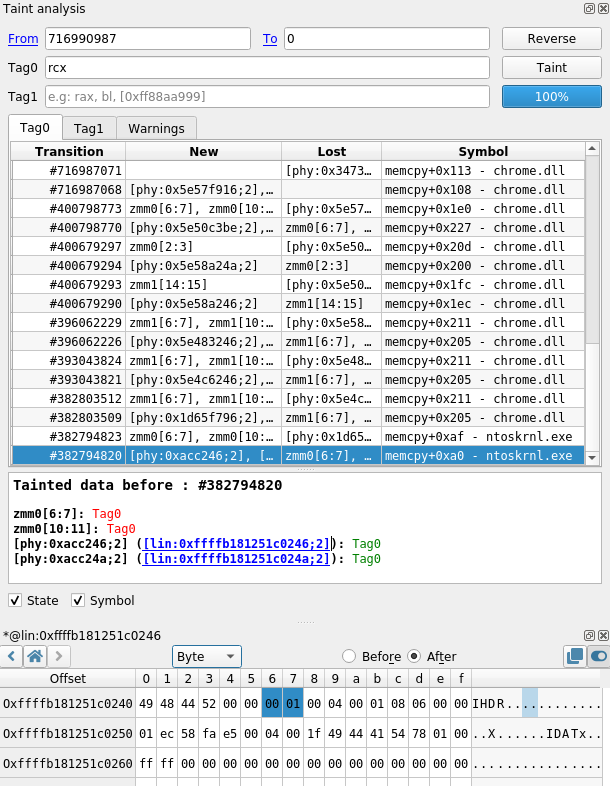
So, somewhere in the code we probably have an integer truncation from 4 bytes to 2 bytes. By looking for more details in the taint, we can see where we transition from 4-byte values to 2-byte values.
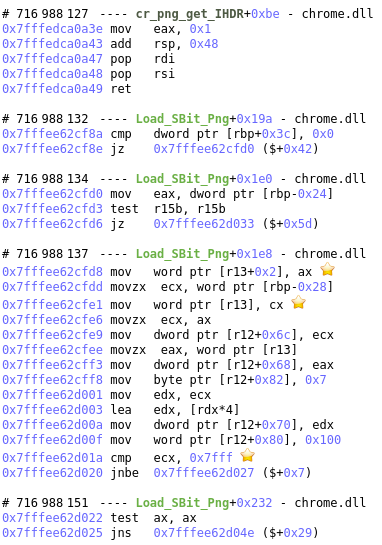
The IHDR header is read in png_get_IHDR and it was called with &imgWidth = rbp - 0x24 and &imgHeight = rbp - 0x28 but as you can see in this assembly code, only the two least significant bytes of each are written in a structure pointed to by r13. Following the taint, we can see that this structure’s fields are transferred to another structure (containing the height and the pitch) and that’s it’s the one used when computing the size just before the call to ft_glyphslot_alloc_bitmap which will allocate the buffer with a wrong size.
We can also see that the program is doing a check on the truncated value to see if they aren’t above 0x7FFF (this is the fix for CVE-2014-9665) but as the check is only done on the truncated values, it won’t fail, except if the values are between 0xF000 and 0xFFFF but not above those limits. The proposed fix is to move this check before the integer truncation.
Conclusion
In the above analysis using esReverse, we tracked the root cause of an exception in Chrome caused by an exploit of CVE-2020-15999. With Timeless Debugging and Analysis, we went from a pagefault, to potentially faulty arguments passed to a function, to the very section of a file triggering the bug in the code. This is another example which demonstrates the capabilities of the Taint feature in esReven and what results you will be able to achieve with it.



