


ALL-IN-ONE PLATFORM
esDynamic
Manage your attack workflows in a powerful and collaborative platform.
Expertise Modules
Executable catalog of attacks and techniques.
Infrastructure
Integrate your lab equipment and remotely manage your bench.
Lab equipments
Upgrade your lab with the latest hardware technologies.


PHYSICAL ATTACKS
Side Channel Attacks
Evaluate cryptography algorithms from data acquitition to result visualisation.
Fault Injection Attacks
Laser, Electromagnetic or Glitch to exploit a physical disruption.
Security Failure Analysis
Explore photoemission and thermal laser stimulation techniques.



EXPERTISE SERVICES
Evaluation Lab
Our team is ready to provide expert analysis of your hardware.
Starter Kits
Build know-how via built-in use cases developed on modern chips.
Cybersecurity Training
Grow expertise with hands-on training modules guided by a coach.




ALL-IN-ONE PLATFORM
esReverse
Static, dynamic and stress testing in a powerful and collaborative platform.
Extension: Intel x86, x64
Dynamic analyses for x86/x64 binaries with dedicated emulation frameworks.
Extension: ARM 32, 64
Dynamic analyses for ARM binaries with dedicated emulation frameworks.
DIFFERENT USAGES
Penetration Testing
Identify and exploit system vulnerabilities in a single platform.
Vulnerability Research
Uncover and address security gaps faster and more efficiently.
Malevolent Code Analysis
Effectively detect and neutralise harmful software.
Digital Forensics
Collaboratively analyse data to ensure thorough investigation.




EXPERTISE SERVICES
Software Assessment
Our team is ready to provide expert analysis of your binary code.
Cybersecurity training
Grow expertise with hands-on training modules guided by a coach.

INDUSTRIES
Semiconductor
Security Labs
Governmental agencies
Academics

ABOUT US
Why eShard?
Our team
Careers



FOLLOW US
Linkedin
Twitter
Youtube
Gitlab
Github





Race conditions detected with a single core

As esReverse emulates a single core machine, a frequent question we receive is if it is possible to use esReven to analyze race conditions. There can be a lot of confusion around what is possible or not, so in this article we hope to address this by giving examples of categories of scenarios that esReven can or cannot analyze.
Don’t know about esReven yet? esReven is a Timeless Debugging and Analysis (TDnA) platform that enables you to record an entire system inside of a VM during a slice of time, and then indexes data about what was recorded and present it to you through a GUI and a Python API, so that you can analyze what happened using the advanced features of esReven, such as the entire history of memory accesses in the recorded trace, or data flow analysis in both forward and backward direction.
Some categories of race conditions
First, what is a race condition? A race condition is a flaw that occurs when the timing or ordering of events affects a program’s correctness (1).
Basically, esReven can analyze race conditions that rely on concurrency, not parallelism. Concurrency is when multiple threads (or processes, remember that esReven records the full system!) compete for running concurrently on the same resource, while parallelism is when multiple threads/processes run simultaneously (because there are eg multiple physical cores to run things at the same time).
A specific kind of race condition is the data race, that occurs when some piece of data is both written to and read from concurrently by unsynchronized threads/processes. Only concurrency, not parallelism, is necessary to observe most data races. However some of them depends on architectural behavior such as per-core memory cache (2). Such data races will not produce the same results with a single processor since its cache would always be fresh. Anyway, esReven currently works at the instruction level and does not attempt to emulate processor caches. Such race conditions cannot be analyzed with esReven.
Furthermore, from C or C++’s point of view, data races invoke undefined behavior (UB) (3). As such, the generated code is not bound to the “as if” rule normally enforced by the compiler (because the input program breaks assumptions made by the compiler). Such undefined behavior can manifest in the generated code eliding e.g. some reads of values (4). This kind of transformations (5) can be difficult to understand after the fact when analyzing the binary code. When using esReven, we might be able to highlight some missing data flow connections using esReven's taint, but it is unclear that this would suffice for the analysis.
OK, what does this leave us? Plenty, actually. Lots of race conditions depend on several threads or processes having unsynchronized access to the same resource (be it memory, a file or something else) over multiple instructions, in which case concurrency is all your need for observing the race condition.
To recap, here are the possible race conditions:

Analyzing a Chrome data race
As an example of a data race that can be analyzed using esReven, let’s do the Root Cause Analysis using esReven of CVE-2021-21166, a data-race-induced buffer overflow in the WebAudio component of Chrome:
-
We start by recording the CVE. This involves installing a vulnerable version of Chrome in a VM prepared to run with esReven, uploading the PoC (from Google Project 0) to that VM, checking it reproduces on the test setup under KVM, and lastly recording the crash. Then the scenario was replayed in around 45 minutes on the author’s laptop, for 37GB of data.
-
Then on to the analysis! From our record (and the framebuffer), we can see that the Chrome tab loading the exploit crashes, so let’s find the crash of the process associated with the crash with a Symbol Call search on ntdll!KiUserExceptionDispatch.
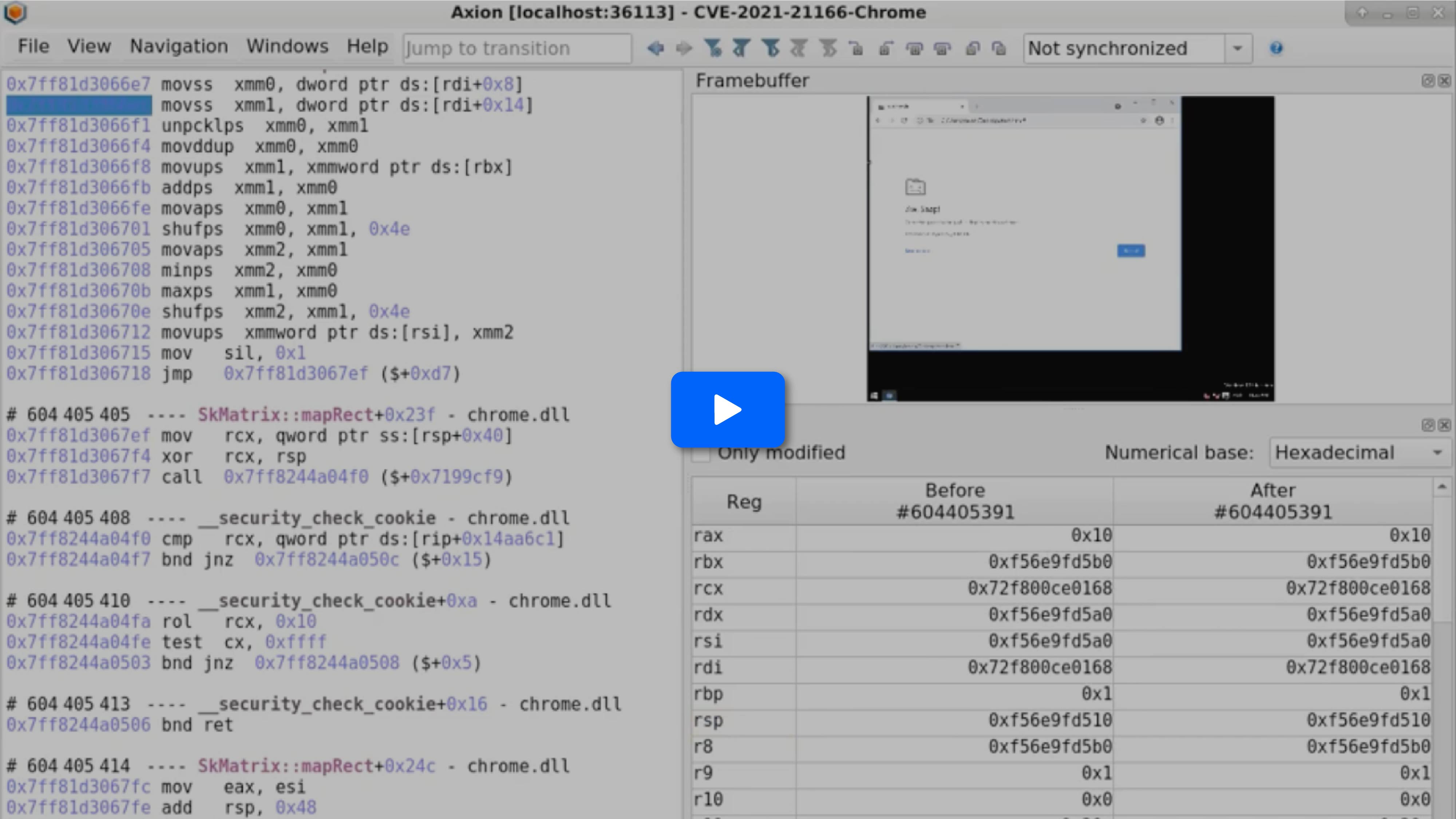
- The crash is caused by a page fault when dereferencing rdi that is not mapped, occurring in the std::sort function from the C++ standard library. Let’s use backward tainting on rdi to find out where the faulty value is coming from!
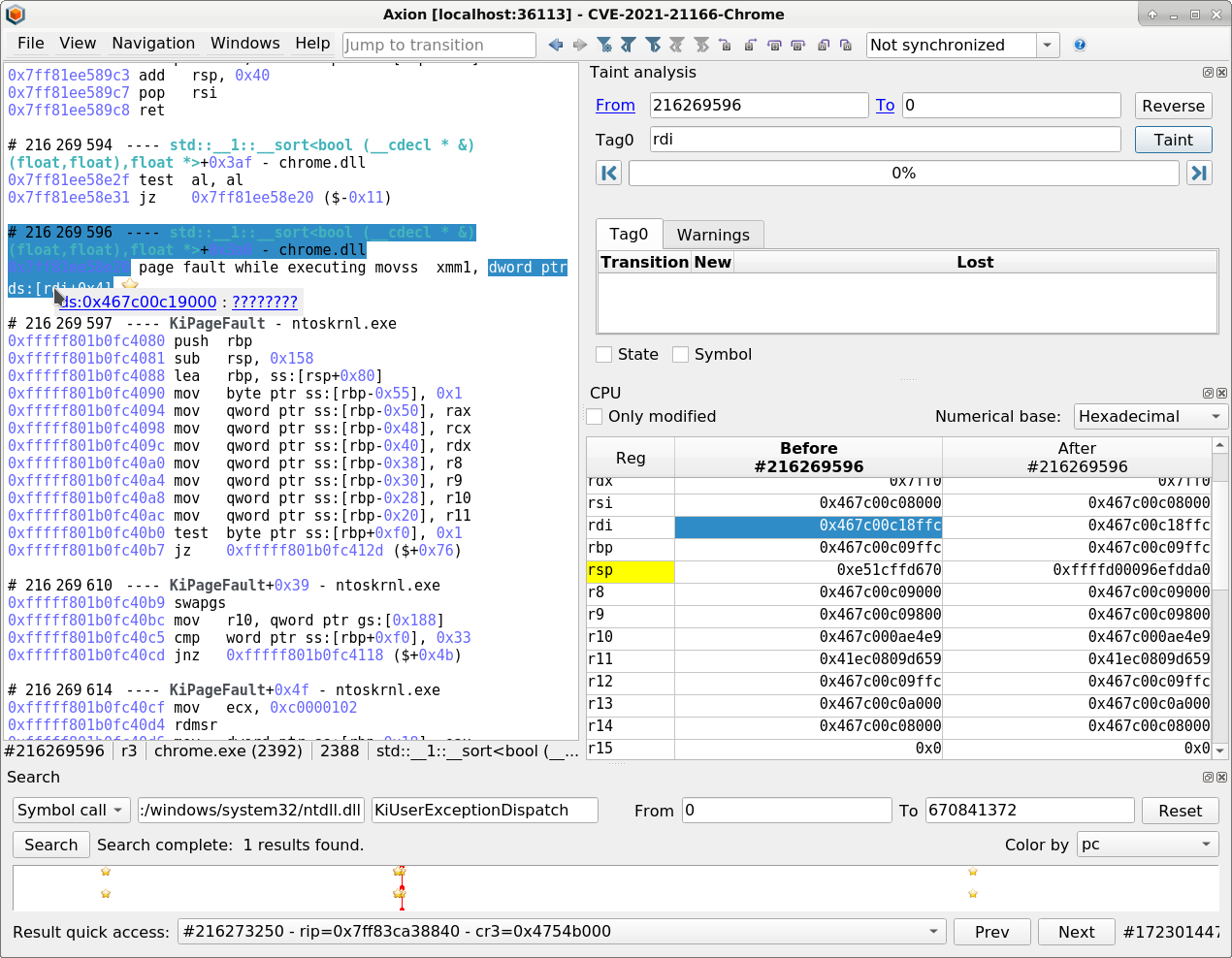
- Backward tainting on rdi indicates that it is used as a kind of “current pointer” for sorting. It is ultimately tracked back by the taint to the first argument of std::sort (ie the rcx register), which is the pointer to the beginning of the buffer that needs sorting.
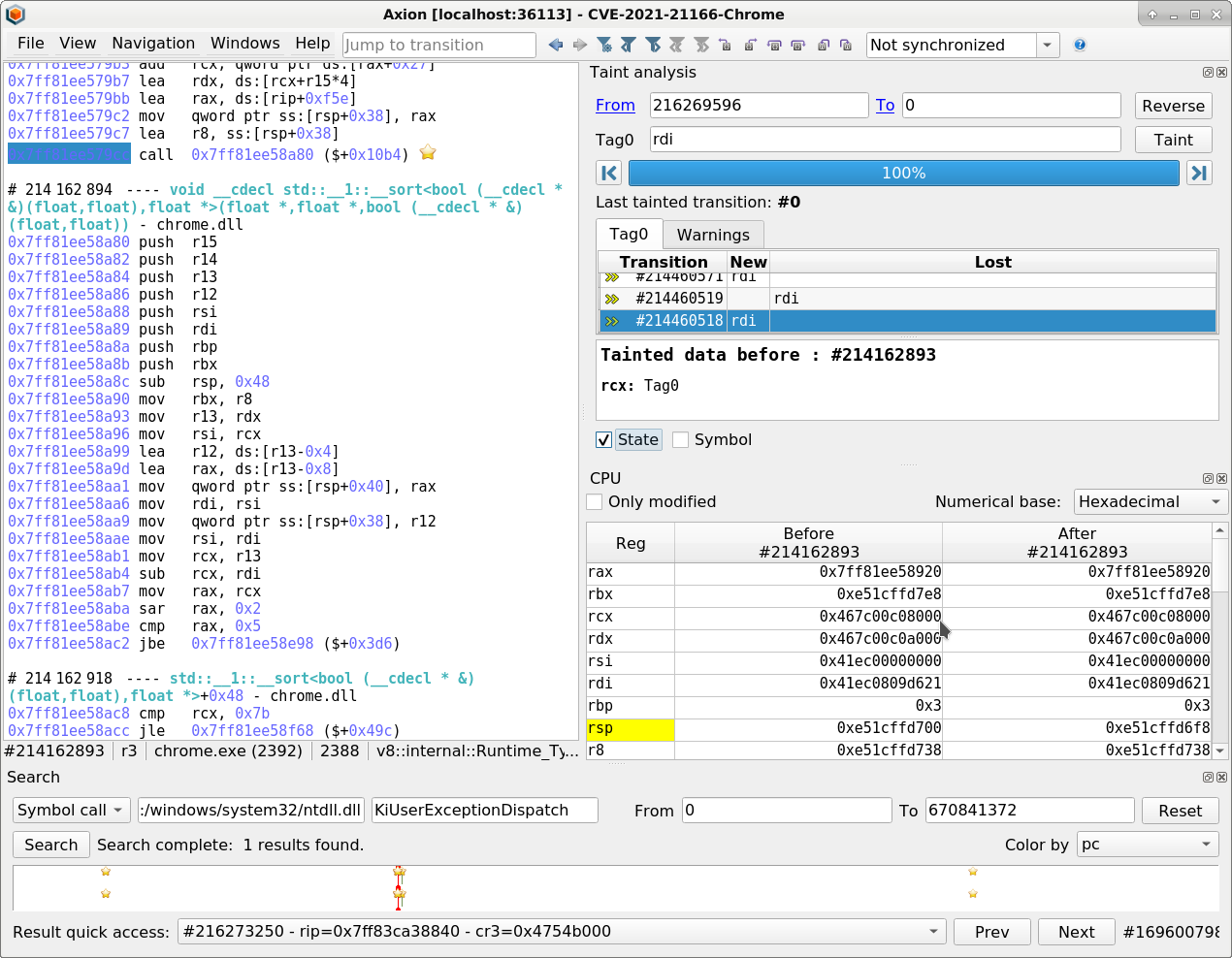
- Applying the memory history on the buffer pointed to by rcx indicates that it is written to during the execution of std::sort.
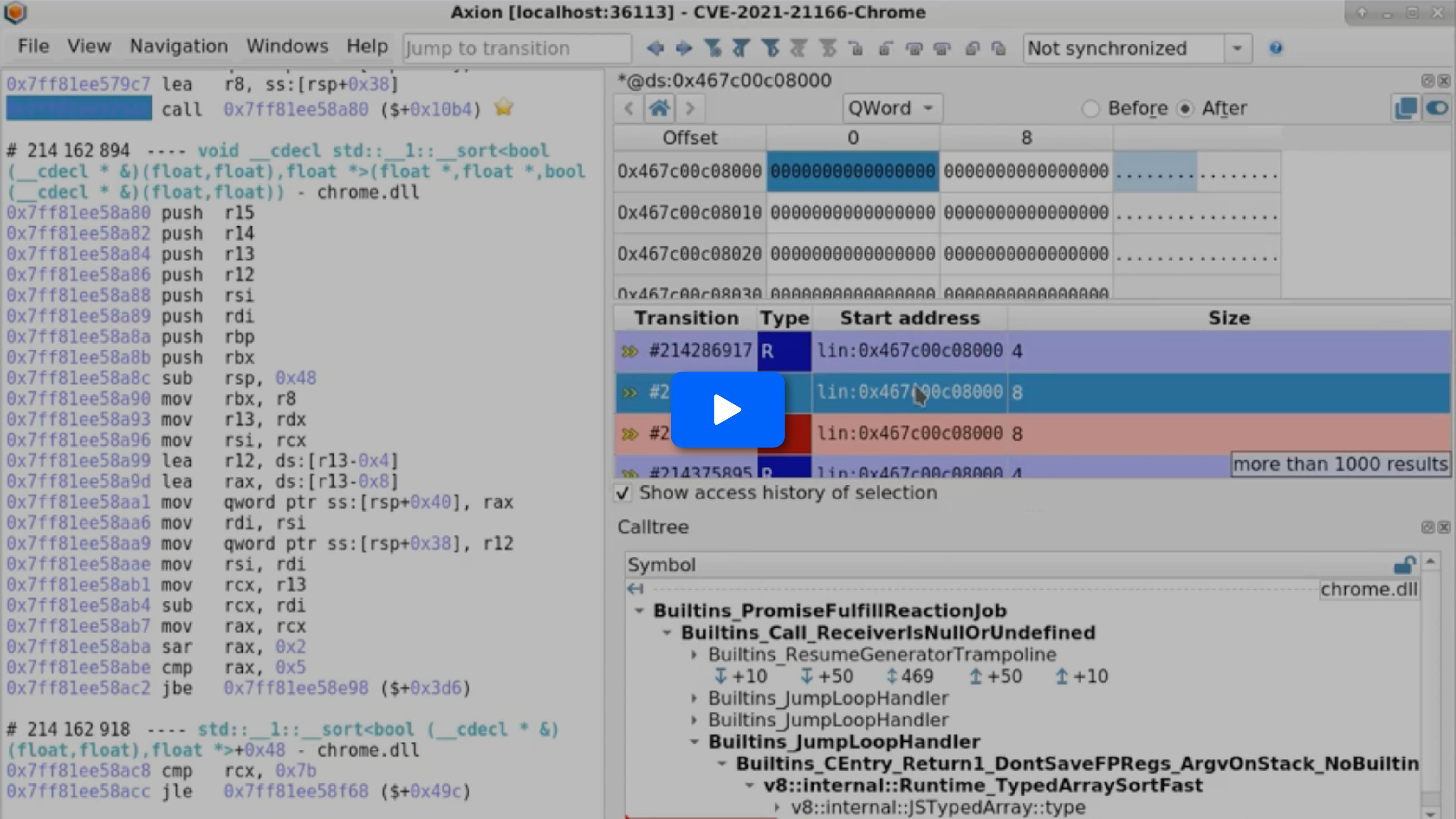
- Going to that write, we can see in the GUI’s status bar that it is being performed by a different thread in blink::AudioBus. Because std::sort is not thread-safe, this write is causing the crash. More specifically, the sort expects to find some sentinel value. Here, it is concurrently rewritten, and as a result it overflows the buffer up until the end of the mapped page.
So yes, as demonstrated, it is possible to analyze such a race condition CVE using esReven on a single core and applying the classic esReven analysis tools (taint, memory history).
Using the API, we could even attempt to automatically detect writes to data from another thread during the execution of a function reading the same data:
import bisect import copy from dataclasses import dataclass import reven2 from reven2.preview.project_manager import ProjectManager pm = ProjectManager("http://127.0.0.1:8880") c = None c = pm.connect("CVE-2021-21166-Chrome") server = c.server crash_ctx = server.trace.context_before(216269596) # found from Axion, could be found automatically crash_tr = crash_ctx.transition_before() call_tr = crash_tr.step_out(is_forward=False) # go to the beginning of the crashing function call_thread = call_tr.context_before().ossi.thread().id # thread that crashed ### Script utils class MemoryRange: """ Represents a range of memory with insertion, union and address-sort """ def __init__(self, address, size): self.address = address self.size = size def union(self, other): left = self.address.offset left_end = left + self.size right = other.address.offset right_end = right + other.size start = left if left < right else right end = left_end if left_end > right_end else right_end if start >= end or ((end - start) > (self.size + other.size)): return None address = copy.copy(self.address) address._offset = start return MemoryRange(address, end - start) def __str__(self): return f"[{self.address} ; {self.size}]" def __le__(self, other): return self.address <= other.address def __lt__(self, other): return self.address < other.address def intersection(self, other): left = self.address.offset left_end = left + self.size right = other.address.offset right_end = right + other.size start = left if left > right else right end = left_end if left_end < right_end else right_end if start >= end: return None address = copy.copy(self.address) address._offset = start return MemoryRange(address, end - start) class MemoryRangeMap: """ A map of non-overlapping MemoryRange to some data. On insertion, ranges that would overlap with the inserted value are merged with the inserted value, and their data pushed into a list associated with the resulting merged range. """ def __init__(self): self.set = [] self.data = {} def insert(self, memory_range, data): data = [data] if not self.set: self.set.append(memory_range) self.data[memory_range.address.offset] = data return index = bisect.bisect_right(self.set, memory_range) if index != 0: previous = self.set[index - 1] union = previous.union(memory_range) if union is not None: memory_range = union del self.set[index - 1] previous_data = self.data[previous.address.offset] del self.data[previous.address.offset] data = previous_data + data index -= 1 while index != len(self.set): next = self.set[index] union = next.union(memory_range) if union is None: break memory_range = union del self.set[index] next_data = self.data[next.address.offset] del self.data[next.address.offset] data = next_data + data self.set.insert(index, memory_range) self.data[memory_range.address.offset] = data def __iter__(self): for memory_range in self.set: yield (memory_range, self.data[memory_range.address.offset]) @dataclass class Data: """ Data to insert in our map """ process_name: str thread_id : int access: reven2.memhist.MemoryAccess ### Script main call_map = MemoryRangeMap() # map for accesses made by the thread that crashed other_map = MemoryRangeMap() # map for accesses made by other threads/processes for access in server.trace.memory_accesses(from_transition=call_tr, to_transition=crash_tr): ctx = access.transition.context_before() thread = ctx.ossi.thread().id process_name = ctx.ossi.process().name data = Data(process_name, thread, access) is_kernel = ctx.read(reven2.arch.x64.cs) & 3 == 0 if is_kernel: # ignore kernel accesses that add a lot of noise. Re-enable if necessary continue if thread == call_thread: call_map.insert(MemoryRange(access.physical_address, access.size), data) else: # ignore reads from other threads that cannot cause synchronization issues to the current thread if access.operation == reven2.memhist.MemoryAccessOperation.Write: other_map.insert(MemoryRange(access.physical_address, access.size), data) # display accesses to shared data: such data is read/write from the crashing thread, and was written from another # thread at least once. for (m, m_data) in call_map: for (n, n_data) in other_map: if MemoryRange.intersection(m, n) is not None: print(f"{MemoryRange.intersection(m, n)}: {m_data[0].process_name}!{m_data[0].thread_id}: {m_data[0].access} ||| {n_data[0].process_name}!{n_data[0].thread_id}: {n_data[0].access}")
Running this script produces the following output:
[phy:0x392efc00 ; 1024]: chrome.exe!2388: [#214852126 movss xmm1, dword ptr ds:[rdi+0x4]]Read access at @phy:0x392ef000 (virtual address: lin:0x467c00c11000) of size 4 ||| chrome.exe!2528: [#214322911 movups xmmword ptr ds:[rcx], xmm0]Write access at @phy:0x392efc00 (virtual address: lin:0x467c00c11c00) of size 8 [phy:0x5fbbe000 ; 512]: chrome.exe!2388: [#214469528 movss xmm1, dword ptr ds:[rdi+0x4]]Read access at @phy:0x5fbbe000 (virtual address: lin:0x467c00c0a000) of size 4 ||| chrome.exe!2528: [#214348370 movups xmmword ptr ds:[rcx], xmm0]Write access at @phy:0x5fbbe000 (virtual address: lin:0x467c00c0a000) of size 8 [phy:0x607c3c00 ; 1024]: chrome.exe!2388: [#214961340 movss xmm1, dword ptr ds:[rdi+0x4]]Read access at @phy:0x607c3000 (virtual address: lin:0x467c00c13000) of size 4 ||| chrome.exe!2528: [#214323020 movups xmmword ptr ds:[rcx], xmm0]Write access at @phy:0x607c3c00 (virtual address: lin:0x467c00c13c00) of size 8 [phy:0x76ee1000 ; 512]: chrome.exe!2388: [#214217721 movss xmm0, dword ptr ss:[rbp]]Read access at @phy:0x76ee1ffc (virtual address: lin:0x467c00c08ffc) of size 4 ||| chrome.exe!2528: [#214348261 movups xmmword ptr ds:[rcx], xmm0]Write access at @phy:0x76ee1000 (virtual address: lin:0x467c00c08000) of size 8
After around 20 minutes execution time, we automatically found the concurrent write accesses from thread 2528 in Chrome! If applied to a function that is not thread-safe, then it means we have a concurrency error. For thread-safe functions, it should be verified if the accesses are protected by a synchronization primitive.
Conclusion
While deterministic replays in the presence of multiple cores is a difficult problem, likely to require hardware probes (6), a full-system TDnA like esReven can be used to analyze a good chunk of race conditions, including those occurring between multiple threads or processes, and including Chrome CVEs. Using esReven, such race conditions can be automatically analyzed end-to-end in about one hour.
(co-written by Louis Dureuil & Quentin Buathier)

Footnotes
-
(2) https://corensic.wordpress.com/2011/08/15/data-races-at-the-processor-level/
-
(3) https://en.cppreference.com/w/c/language/memory_model#Threads_and_data_races
-
(5) On UB allowing compilers to do whatever with your code, here’s a couple of interesting references:
-
(6) “The best hope for general, low-overhead parallel recording seems to be hardware support.” in O’Callahan, R., Jones, C., Froyd, N., Huey, K., Noll, A., & Partush, N. (2017). Engineering record and replay for deployability. In 2017 USENIX Annual Technical Conference (USENIX ATC 17) (pp. 377-389).


