

Plug REVEN to your fuzzing pipeline and take advantage of Timeless Debugging and Analysis
by Skia
Categories: Technical -
Tags: Reverse Engineering - REVEN - Fuzzing - AFL - Workflow API -
Ever wondered how you could integrate REVEN with your fuzzing pipeline, to automatically record the crashes you find and have them ready for analysis without manual intervention? Fear not, this is actually very easy thanks to the automatic recording API provided by REVEN Enterprise and a small piece of Python! Part of the analysis itself could also be automated for triage, filtering or having a report ready for the analyst. This aspect is not covered in this article (look at this demo if interested).
Requirements
- On the server side:
- A running REVEN Enterprise Project Manager, accessible from the network if client is remote.
- A QEMU VM registered in that Project Manager, fully prepared for the autorecord, and of course able to run the fuzzed binary, whether Windows or Linux.
- On the client side (that can be implemented on the server itself):
- A fuzzer’s output folder somewhere on the file system, or any other input file corpus, with the corresponding binary.
- A Python 3 environment with the
reven2package installed and with theautomatic-post-fuzzer-recorder.pyscript able to run.
The following figure illustrates the setup:
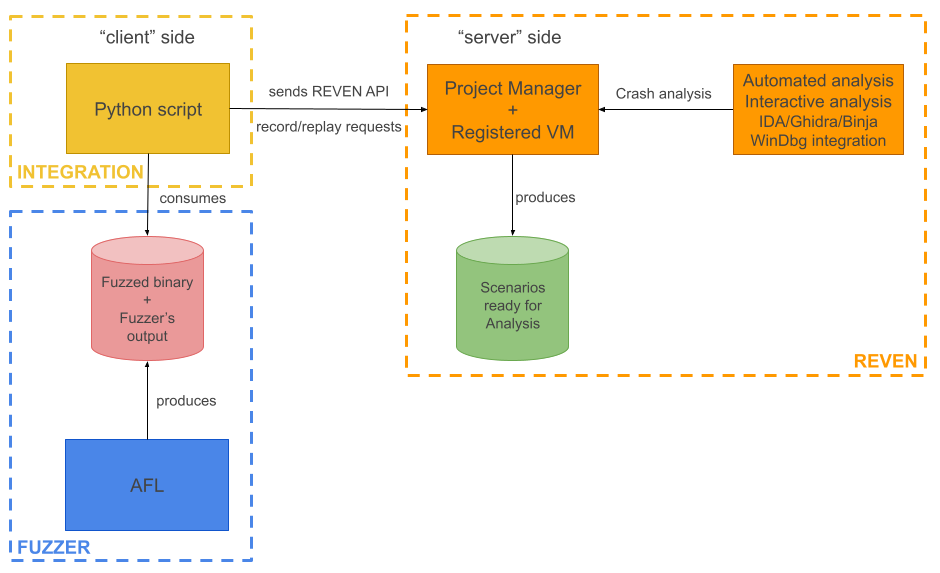
Gluing both worlds, fuzzer and REVEN
As you probably already know if you are into fuzzing, AFL and other fuzzers produce an output folder with all the inputs that generated a crash. It is this output folder that we will use to automatically record a scenario per crash.
The automatic-post-fuzzer-recorder.py
script
currently does the job of recording multiple scenarios automatically on a REVEN Project Manager.
It will take as input a binary and a corpus of files, that typically is a fuzzer’s output, and will record one scenario per corpus file, feeding the binary with the corpus file name as first argument. Once a record is done, the corresponding replay is launched, and the next record will be performed. Between each record, the VM’s live snapshot will be restored.
Every scenario is named with the prefix given in argument, the binary name, and the corpus file name. If a scenario with the same name already exists, this script will exit, meaning you won’t overwrite your existing scenarios by re-running it a second time. Also, this script will not “listen” to the directory, meaning it is not suitable for running during the fuzzer’s execution, but rather after its termination.
From this version, it should be quite straightforward to adapt the script for some other use cases that better fit your needs.
Let’s dive a bit into its usage.
A typical invocation looks like this:
python3 automatic-post-fuzzer-recorder.py \
--url http://127.0.0.1:8880/ \
--snapshot 1 \
--live-snp 'autorecord-2048M-net-nokvm' \
--name "fuzzing-mybinary" \
--corpus path/to/mybinary/output/crashes/ \
--local-binary path/to/mybinary/a.exe
--urlis the address of the REVEN project manager--snapshotis the ID of the VM disk snapshot you want to use--live-snpis the name of the live snapshot on this disk snapshot used for each record--nameis a prefix that will be prepended to each scenario’s name--corpusis the path to a folder containing the input files you want to record--local-binaryis the path to your local binary that you want to record
Running this with three files in the corpus returns the following output:
binary file "a.exe" uploaded with id 39
QEMU session started
input file "id:000002,sig:11,src:000000,time:33720,op:havoc,rep:32" uploaded with id 40
Scenario "fuzzing-mybinary - a.exe - id:000002,sig:11,src:000000,time:33720,op:havoc,rep:32" created with id 18
Snapshot "autorecord-2048M-net-nokvm" loaded
Record started
Recorder status: Record completed
Record saved in scenario fuzzing-mybinary - a.exe - id:000002,sig:11,src:000000,time:33720,op:havoc,rep:32
Replay started for scenario 18
input file "id:000000,sig:11,src:000002,time:30099,op:havoc,rep:4" uploaded with id 41
Scenario "fuzzing-mybinary - a.exe - id:000000,sig:11,src:000002,time:30099,op:havoc,rep:4" created with id 19
Snapshot "autorecord-2048M-net-nokvm" loaded
Record started
Recorder status: Record completed
Record saved in scenario fuzzing-mybinary - a.exe - id:000000,sig:11,src:000002,time:30099,op:havoc,rep:4
Replay started for scenario 19
input file "id:000001,sig:11,src:000002,time:30561,op:havoc,rep:32" uploaded with id 42
Scenario "fuzzing-mybinary - a.exe - id:000001,sig:11,src:000002,time:30561,op:havoc,rep:32" created with id 20
Snapshot "autorecord-2048M-net-nokvm" loaded
Record started
Recorder status: Record completed
Record saved in scenario fuzzing-mybinary - a.exe - id:000001,sig:11,src:000002,time:30561,op:havoc,rep:32
Replay started for scenario 20
All files from the corpus were recorded, exiting.
Session has been stopped
Created scenarios have been dumped to 'created_scenarios.json'
As you can see at the end of the output, a created_scenarios.json file provides a complete
summary of the scenarios that were recorded.
It can be used to launch analysis scripts on those scenarios, such as specific reports (crash detection for example) or vulnerability detection.
Some thoughts on performance
My machine has an Intel i5-8500 CPU, 16 GB of RAM, and all the REVEN-related data for this are stored on a SATA-connected Samsung 860 EVO SSD.
This run took about one minute to complete, and each replay took about 30 seconds each. The used binary does little more than opening the input file and sometimes failing depending on the content, which gives us a good estimation of the speed of the whole process without too much overhead from the scenario itself.
Most of the time here was spent in the reloading of the VM snapshot and getting the autorecorder ready.
Going further
This simple setup can work great for simple cases as the one presented above, but of course there is room for improvements. Here are a few ideas:
- Plugging some analysis scripts afterwards, so that reports could be generated automatically on the recorded scenarios to help triage the fuzzer output more efficiently.
- Integrating more deeply in a real fuzzing pipeline, to avoid manually running the script for each fuzzing campaign. One can imagine many different directions here, depending on the setup it integrates with.
- Using multiple machines to record and replay separately, leveraging for example the import/export feature, would probably be a good idea if the load generated by the replay was to impact too much the recording performances.
As this setup mainly relies on Python, a lot can be imagined and done, even in the most complicated setup!
This article demonstrated how REVEN can be integrated inside a fuzzing toolchain to automatically generate timeless analysis scenarios for the chain’s outputs. This scenarios can then be further analyzed, still automatically with the Python API or manually using Axion or even Windbg for Windows scenarios.
If this article resonates with some of your needs or if you have questions about the implementation, feel free to contact support.
